1. 简介
深度学习作为机器学习的一个分支,近年来受到了广泛的追捧和应用,但其庞大的运算量一直是制约其发展的瓶颈,因此近年来也涌现出了一系列的神经网络优化方法,本文结合自身的一些工作心得,简单介绍一些深度神经网络的优化方法。
目前,主流的深度神经网络结构有MLP, CNN, RNN等,但针对它们的优化方法都是类似的,因此本文主要介绍FeedForward 网络的优化。
1.1 FeedForward
前向网络的推理计算大体可以分为两步:
- 对输入做仿射变换:
- 激活函数做非线性变换(常用的激活函数有 Sigmoid, RELU,分类任务中,输出层的激活函数则常采用Softmax):
其中\(h_i\) 是第\(i\)个隐藏层的输出,\(W_i\)是对应的权值矩阵,\(b_i\) 是对应的偏置向量。
本文的内容也将围绕上述两步展开。
2. 计算优化
2.1 归一化处理
通常,机器学习的算法都要求对输入的特征向量做归一化处理,即
其中\(\mu\)为均值,\(\sigma\)为标准差。
为了减少计算量,可以将上述过程与第一层的仿射变换(\(W_1 \bar{x} + b_1\))合并,
令\(W_1 = \frac{W_1}{\sigma}, b_1 = b_1 - \frac{W_1}{\sigma} \mu\),则可以保证在数学运算结果一致的情况下,节省了输入归一化带来的运算量。
2.2 优化仿射变换
在给定 DNN 模型的情况下,计算的核心其实就是矩阵运算,根据输入的不同,可能会有矩阵矩阵,向量矩阵,向量*向量三种运算,其大部分的运算量都消耗在仿射变换上,因此对仿射变换进行优化至关重要。
2.2.1 FanIn & FanOut
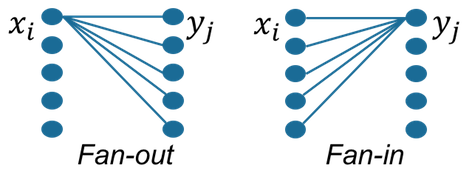
FanIn 和 FanOut只是矩阵乘法之间的运算顺序不一样,它们的使用主要取决于权值矩阵在内存中的存放顺序(数据的稀疏性也有一定影响,详见下一小节),以向量*矩阵运算为例,
其中\(\mathbf{y}\in \mathbf{R}^{1\times m}\), \(\mathbf{x}\in \mathbf{R}^{1\times n}\), \(\mathbf{W}\in \mathbf{R}^{n\times m}\).
- FanIn
1
2
3
4
5
6
7
8
9
for(int i = 0; i < m; i++)
{
float accVal = 0.0;
for(int j = 0; j < n; j++)
{
accVal += x(j) * W(j, i);
}
y(i) = accVal;
}
- FanOut
1
2
3
4
5
6
7
for(int j = 0; j < n; j++)
{
for(int i = 0; i < m; i++)
{
y(i) += x(j) * W(j, i);
}
}
如果矩阵是按行存储(矩阵同一行中相邻元素存储在相邻的内存空间内),则应采用FanOut的计算方式,若按列存储(矩阵同一列中,相邻元素存储在相邻的内存空间内),则应采用FanIn的计算方式。
FanIn 和 FanOut加速的本质在于:增加Cache的命中率,减少数据存取的时间开销
2.2.2 稀疏性处理
数据的稀疏性优化主要针对输入数据,依然以上面向量*矩阵的运算为例,假如数据数据是稀疏的,那么下面的代码显然具有更高的计算效率:
1
2
3
4
5
6
7
8
9
10
for(int j = 0; j < n; j++)
{
if(x(j) != 0.0) //如果等于0,则无需后续计算
{
for(int i = 0; i < m; i++)
{
y(i) += x(j) * W(j, i);
}
}
}
针对上述向量*矩阵的运算,对于数据稀疏的情况,显然FanOut具有更高的运算效率。
另外,如果DNN中选用RELU作为激活函数,那么可以使得激活函数的输出向量/矩阵具有更高的稀疏性(约50%),从而大幅减少仿射变换的计算量,因此在性能符合要求的情况下,应尽量选择RELU作为激活函数。
2.3 优化激活函数
激活函数的优化主要是针对 Softmax:
显然,如果
那么
并且由于
因此对于
每次计算是否减去常数项\(z_{max} + \log (\sum e^{z_j - z_{max}})\) 并不会改变最终的竞争条件,即相互之间的大小关系,因此模型在推理计算时,如果不需要概率值,可以移除 Softmax 的计算,直接采用仿射变换的结果即可。
3. 量化与压缩
在数学上对DNN的推理过程进行优化之后,后续的优化则主要围绕工程实现进行。
3.1 定点化
目前,对于大部分的嵌入式设备而言,定点的运算速度要快于浮点的运算,因此,对DNN的输入和权值进行定点化,可以大幅的提升计算效率同时降低模型大小。
以8bit定点化为例,需将浮点的权值映射到\([-128, 127)\)这个区间上,因此,权值的缩放倍数为
其中\(S\)为权值映射的缩放倍数,\(W_f\)为浮点权值矩阵。
定点化后,下面等式成立:
其中\(W_f, B_f\)为浮点的权值矩阵和偏置向量,\(W_i, B_i\)为定点的权值矩阵和偏置向量。
3.2 优化缩放倍数
完成上述定点化后,DNN前向传播时,每往后传播一层,依然要做浮点的除法(可转换为浮点乘法),依然会有浮点运算,如何将这部分浮点计算也优化掉呢?
在程序实现中,我们常将除以\(2^n\)优化为向右移位\(n\)位,因此,我们可以对缩放倍数\(S\)进行优化,
一般取\(Q\)为\(2^n\),从而将除法转换为移位计算,同时保证比较高的定点化精度。
3.3 稀疏性处理
统计DNN的权值矩阵,我们可以发现,每一层的权值都大量分布在\(0\)周围的某个小区间内,如下图:
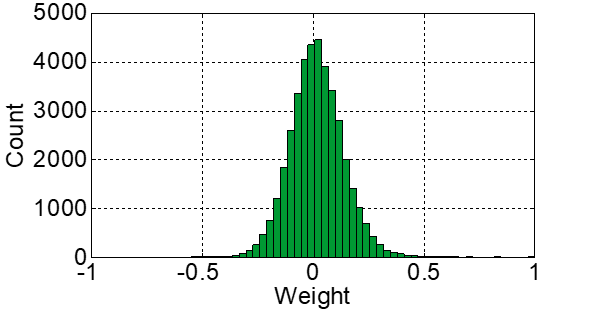
因此,为了保证尽可能高的精度,同时不增加太多的存储空间和计算量,我们允许有一定量的权值(比如%2)在定点化后位宽大于8 。在具体的实现中,采用两个权值矩阵\(W_L\)和\(W_H\)分别表示定点化权值的低8位和高8位,此时有
其中\(W_H\)是一个极度稀疏的矩阵,因此并不会增加太多的计算量和存储空间,但却能大幅提高模型的精度。
4. 其他优化方法
- SIMD 优化
- Lazy Evaluation(在语音识别领域,跳帧处理,既可以降低计算量,同时保持性能基本不变。)
- 模型剪枝
- 知识蒸馏
- SVD 分解
5. 总结
采用上述优化后,可以实现:
- 大幅提高计算效率
- 大幅压缩模型大小
- 模型精度只有轻微的损失
上述内容主要基于近期做的一些神经网络的优化工作,使得神经网络可以在低功耗的嵌入式设备上运行,因此特将整个过程中的一些心得体会记录下来,若有不当之处,欢迎交流指正。