1 简介
随着 DNN 的兴起,它被广泛应用于语音识别领域,但在端到端的语音识别成熟之前,基于HMM(Hidden Markov Model)的声学模型依然是当前语音识别系统的主流方案,而状态绑定(state tying)是 HMM 声学建模过程中不可或缺的重要一环。
1.1 何为状态绑定(State Tying)?
以英文为例,我们一般采用 triphone 作为建模单元,但是英文phoneme 一般有40个左右,那么 triphone数量为\(40^3\)个,显然若我们对所有的 triphone 建模,那么需要海量的训练数据,这显然是不现实的,因此我们需要把一些发音比较相似的 triphone合并在一起,降低参数空间的大小,在模型复杂度和训练数据之间实现一个较好的平衡。
直观的想法:我们可以对发音相似的 triphone 做聚类,从而减小模型复杂度,但这样做存在存在几个问题:
- 泛化性能如何保证?即对于训练数据中没有的 triphone,它该聚到哪一类才能获得更好的性能呢?
- 聚类后的 triphone,其实就是多个 triphone 的均值,它降低了模型的描述精度。一般来说,在 HMM 中,我们会用三个 state 对一个 triphone 进行建模,假设我们有两个 triphone,它们左边的 phoneme 都是一样的,只有右边的 phoneme 不一样,如下图:
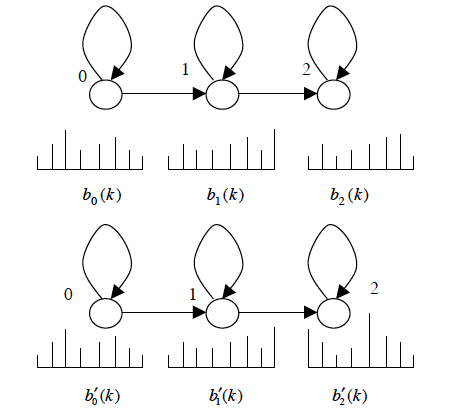 由于左边的 phoneme 是一样的,因此它们的第一和第二个 state 的概率密度分布应该基本一致,而第三个 state 的分布有较大的差别,如果我们以 triphone 为单元进行聚类,那个聚类后第三个 state的分布将变得极其不精准。
由于左边的 phoneme 是一样的,因此它们的第一和第二个 state 的概率密度分布应该基本一致,而第三个 state 的分布有较大的差别,如果我们以 triphone 为单元进行聚类,那个聚类后第三个 state的分布将变得极其不精准。
更好的做法是在 state 这一层面做聚类,这也就是本文讲的状态绑定。还是以上图为例:我们可以将两个 triphone 的第一个和第二个 state 分别聚类在一起,而第三个 state 不聚在一起,从而在降低模型复杂度的情况下,保证了模型有更高的精度。
1.2 有何意义?
使用状态绑定有以下几点好处:
- 降低对训练数据量的要求
- 解决某些建模单元(triphone) 训练数据不足的问题,提高模型的泛化性能。
- 降低参数空间大小,提高训练和识别的效率。
2 状态绑定的具体实现
2.1 state tying
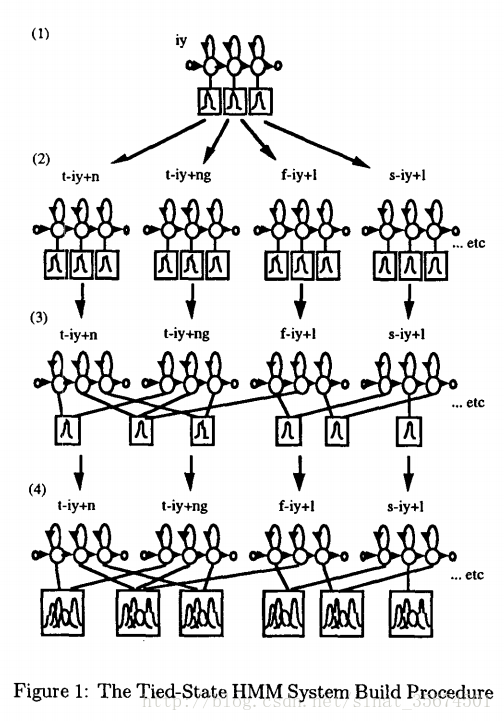
下图显示了一个状态绑定的HMM 系统的创建过程过程,主要包含四步:
-
用单高斯输出概率密度函数创建和训练一个初始化的3状态从左到右的monophone 模型;
-
克隆这些monophone 的状态来初始化所有相关的 triphone,状态转移矩阵不进行克隆,然后进行Baum-Welch训练。
-
训练好后,对于从相同的monophone得到的triphone的集合,对相应的状态进行聚类,对每一个结果类中,选择一个典型的状态作为样例,然后这一类的其他所有成员都聚到这个状态。
-
增加一个状态的高斯数,并对模型进行重估,直到在验证集上性能达到要求或者混合高斯组建的数量达到预设值。
按上述过程,第一次产生的模型的性能可能会比较差,因此需要不断迭代,重复上述构建过程。
2.2 tree-based state clustering
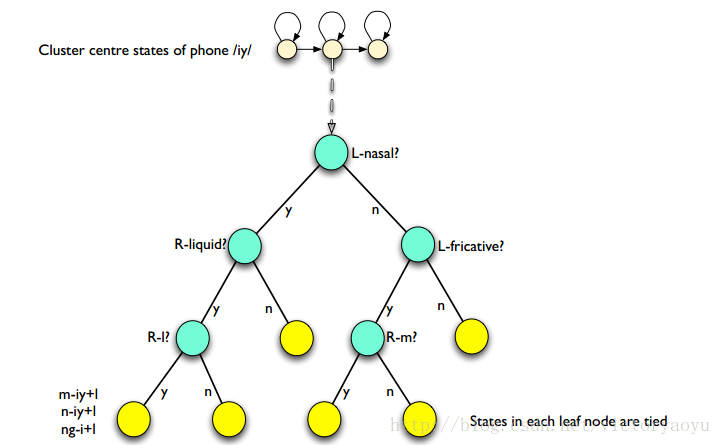
在上一节中的第三步,状态的聚类是通过决策树来实现的。假设每个 triphone 有三个状态,那么我们需要为每一个状态都构建一颗决策树。同一个 monophone 产生的 triphone 的相同位置的状态组成一个状态池,然后对状态池中的状态进行聚类。池中所有的状态共享一个根节点,通过question来分离状态池,生长决策树,最终树叶就是状态聚类的结果。树的生长过程如下:
- 首先按照最大化对数似然的原则,从预先定义的questions set(更好的方法是通过 data drive 的方式自动生成问题集)中的挑选一个问题,将当前节点分离为两个子节点。
- 重复上述过程,迭代直至对数似然增量小于预先设定的阈值,或者当前节点下的数据小于阈值。
下图显示了某个 triphone 的中间状态的决策树:
对于某一个树节点,它的对数似然为:
其中 \(S\) 是某树节点的状态池,\(F\)是对应的训练数据,\(\mu(S)\)和\(\Sigma(S)\)是状态的均值和方差,\(\gamma_s(o_f)\)是观测值\(o_f\)由状态\(s\)生成的后验概率(即state occupation probability)。
当 P服从高斯分布时:
如果 \(S\) 要分裂为两个子节点\(S_y(q)\) 和\(S_n(q)\),那么需要通过最大化下式,找到最佳的 question q*.
3 总结
基于决策树的状态绑定,就是利用决策树,对triphone的HMM状态进行聚类,可以很好的解决数据稀疏的问题;同时决策树也能很好地解决unseen triphones,提高泛化性能。水平有限,若有不当之处,欢迎指正!
Reference
- 《Spoken language processing》
- 《Tree-Based State Tying for High Accuracy Acoustic Modelling Basics Triphone Tying Decision Trees 》, S.J. Young, J.J. Odell, P.C. Woodland 1994.