声纹识别的技术演变(五)
在DNN-Ivector之后, 有越来越多的使用Embedding 和 E2E 的方法来进行声纹识别的文章,并且都取得了不错的效果。。
1 Embedding
1.1 d-vector
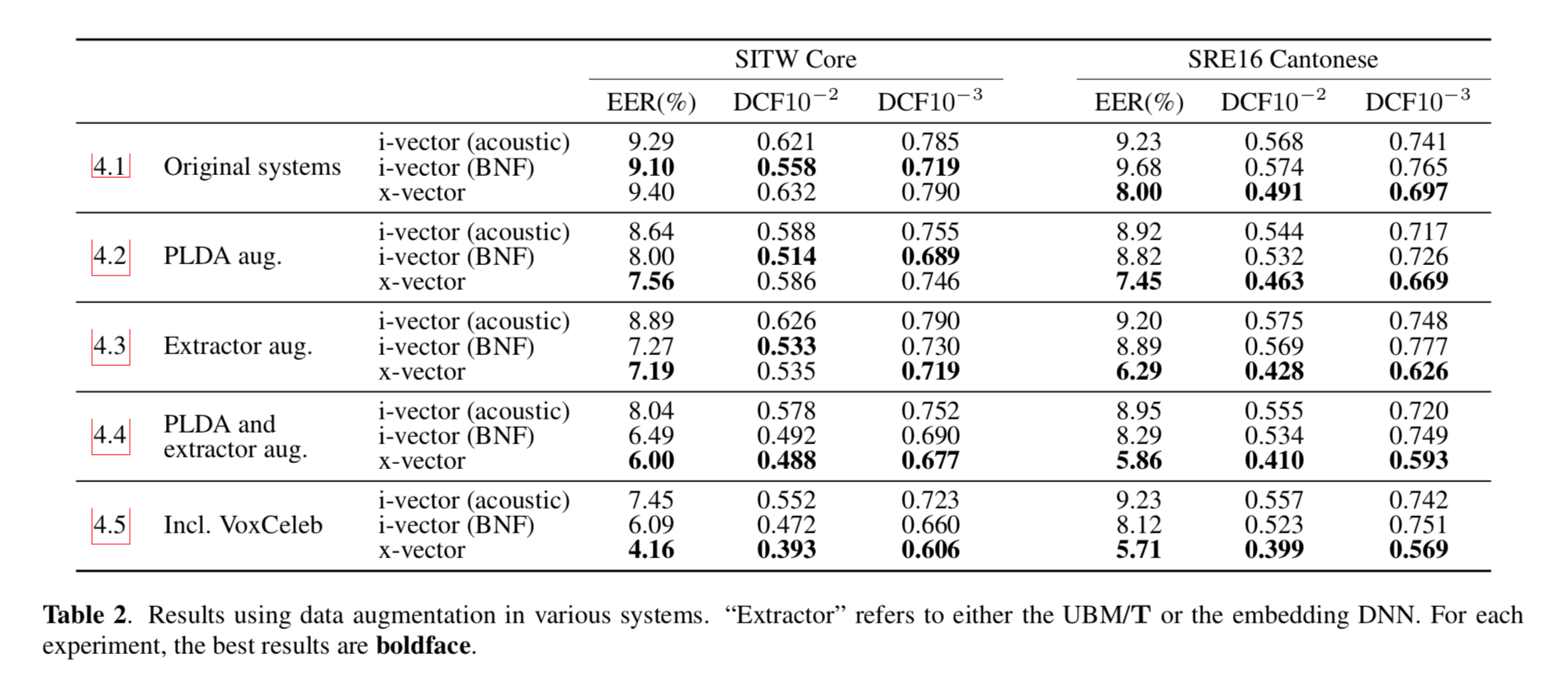
Google于2014年提出了dvector(Reference [1,2]), 它使用了一个四层的全连接层的网络来完成文本相关的声纹识别任务。它的结构如下:

它以40维的FilterBank作为输入特征(context=3,取前后各一帧),speaker作为分类目标(训练时采用了帧级别(Frame-Level)的特征,softmax作分类),将所有隐藏层当做特征提取器,最后一个隐藏层的输出作为特征,采用average pooling,生成d-vector,采用cosine distance得到score/confidence.
但其效果并未超越ivector,只有在噪声的场景下,它的鲁棒性略好一些。
1.2 xvector
xvector由kaldi的团队提出(Reference [3]),采用了kaidi中的TDNN生成speaker的embedding,其网络结构如下图
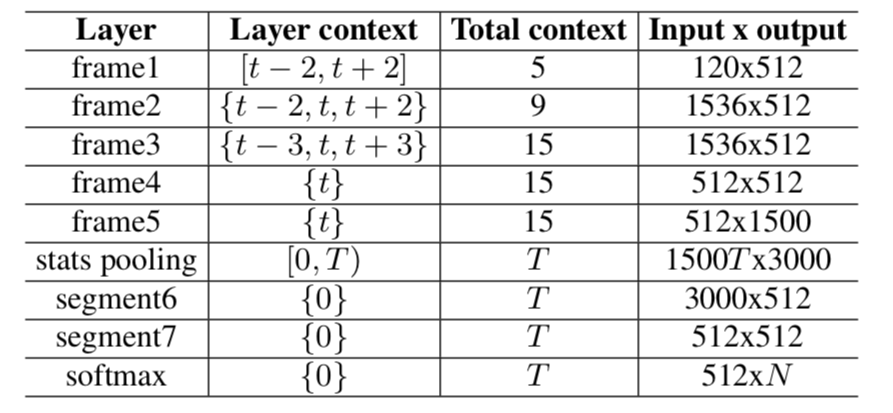
它采用了
- TDNN获取更长的context
- Utterance-Level的特征计算Loss
- Data Augmentation
- PLDA作为打分后端
在数据量较大的时候,可以取得很好的效果。
1.3 Self-attentive xvector
Yingke Zhu等人在Reference [4]中提出用self-attention layer替换average pooling layer,进一步提升了xvector的性能。

其基本思想为:
- pooling 层采用了求平均的方式,每个frame对speaker的判决贡献时一样的
- 不同的frame对speaker的判定应该具有不一样的贡献,通过使用self-attention学习得到相应的权重,使得embedding 可以更好的表征说话人空间。
2 End-to-End
和 Embedding 的结构相比,End-to-End不需要再把训练好的网络再去掉最后的那么一两层,直接输入两段语音就可以判断这语音是否来自同一个人。
2.1 End-to-End
下面还是以两片分别来自Google和kaldi团队的论文来简单说明End-to-End的实现。
2.1.1 dvector-based
Google在d-vector的基础上,将Enroll、Evaluation 全部融合在一个网络里(Reference [5]),其结构如下

其中LSTM的结构如下图
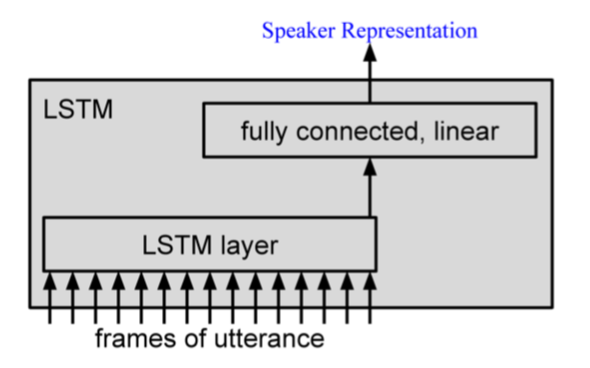
- Training
- Only connect the last output to the loss to obtain a single, utterance-level speaker representation
- Sample for each training utterance only a few utterances from the same speaker to build the speaker model at training time
-
Loss:
Where
- Evaluation
- Enrollment 经过DNN/LSTM提取speaker representation(Embedding),然后对多条utterance的speaker representation取平均,得到speaker模型
- Evalution 经过DNN/LSTM提取该条utterance的speaker representation,与speaker模型计算cosine distance,然后经过logistic classifier,输入大于0.5则target,否则nontarget。
相比于baselien的d-vector模型,性能有了大幅提升。
2.1.2 xvector based
Kaldi团队的End-to-End模型(Reference [6]),其网络结构如下
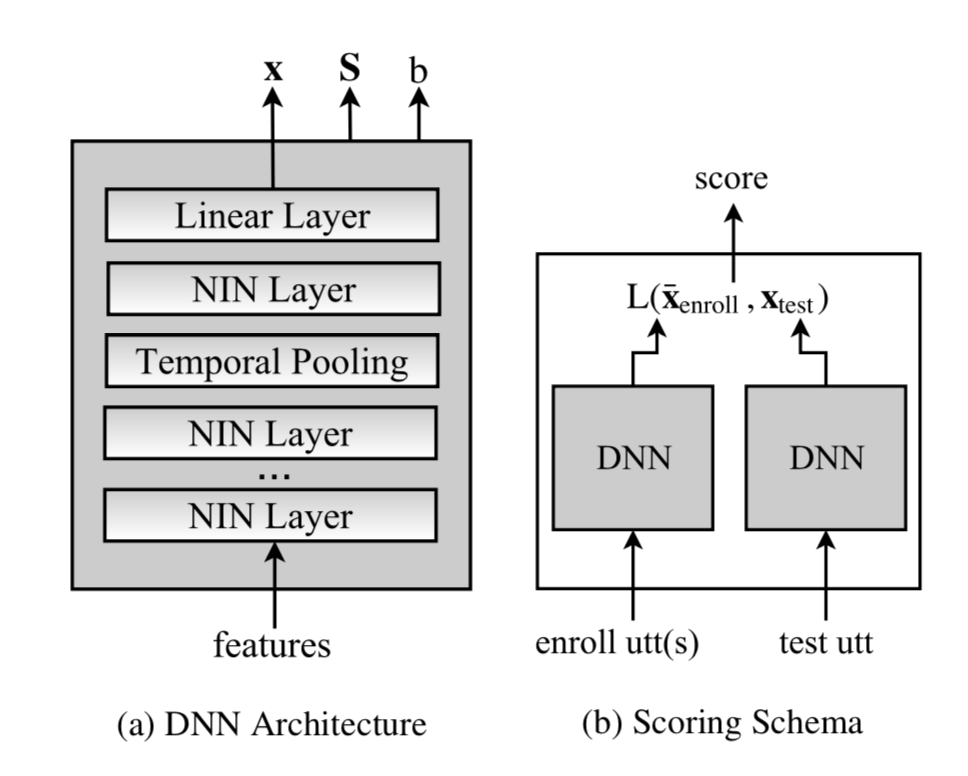
它采用了两个DNN网络作为打分后端,对于embedding $x$ 和 $y$,使用logistic function来表示它们来自同一个speaker的概率。
其中,$L(x,y)$为距离度量,采用了类似PLDA的机制,即最大化类间距离,最小化类内距离。
它在训练的时候有几点需要注意:
- 训练数据中应包含不同duration的音频
- 先使用duration较长的样本,否则系统可能无法稳定收敛,然后再使用不同长度的音频训练。
- Shuffle
- 每个minibatch都应包含不同声道的数据,保证声道的多样性。
相比ivector的baseline模型,它的性能得到大幅提升。
2.2 Triplet Loss
自从 triplet loss 在人脸识别中取得成功之后,也很多人(Reference [7-9])在声纹识别中也用了 triplet loss,并取得了不错的效果。
3 Conclusion
尽管DNN在声纹领域已经掀起一片热潮,但ivector+PLDA的技术依然坚挺,知乎上有一个这样一个问题:为什么在说话人识别技术中,i-vector+plda 面对神经网络依然坚挺? 在此引用知乎上高票答主的回答:
为什么在语音识别中dnn的应用会带来如此明显的性能提升,在说话人任务却给人一种挣扎的感觉? 我觉得这跟任务属性是直接相关的。 语音识别的深度学习框架,输出是senone,本质上不存在集外的概念。任何一句话里边的音素都可以在输出层找到它对应的节点,当帧准越高,一般语音识别的正确率也就越高。相对于GMM 这种生成模型,类别确定,不存在集外情况,当然是鉴别性训练(dnn + softmax ce)会好了。但是说话人识别不一样,我们不可能要求测试的人在训练过程中出现过,更不可能直接训练一个所有人的分类器。因此我们希望找到一个隐变量空间,每个人都是这个空间里的一个点,可以用这个空间的一组基来表示。ivector 就是找到了这样的一个隐变量空间。
纵观声纹识别的技术演变过程中,可以看到前辈们的不懈努力。
- GMM的语料不够,提出UBM
- GMM-UBM中,又发现了信道干扰,提出JFA
- JFA的计算复杂和语料不够的情况下,提出I-Vector
- 为了提升噪声的鲁棒性,I-Vector进一步进化到DNN
技术的发展一步步的推动这声纹技术走向实用,声纹领域这两年的持续火热,必将进一步推动声纹技术的发展。
Reference
[1] DEEP NEURAL NETWORKS FOR SMALL FOOTPRINT TEXT-DEPENDENT SPEAKER VERIFICATION
[2] Locally-Connected and Convolutional Neural Networks for Small Footprint Speaker Recognition
[3] X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
[4] Self-Attentive Speaker Embeddings for Text-Independent Speaker Verification
[5] End-to-End Text-Dependent Speaker Verification
[6] DEEP NEURAL NETWORK-BASED SPEAKER EMBEDDINGS FOR END-TO-END SPEAKER VERIFICATION
[7] TRISTOUNET: TRIPLET LOSS FOR SPEAKER TURN EMBEDDING
[8] End-to-End Text-Independent Speaker Verification with Triplet Loss on Short Utterances
[9] Deep Speaker: an End-to-End Neural Speaker Embedding System