1. 目的
Feedforward sequential memory networks 来源于数字滤波器的设计灵感: FIR 滤波器随着阶数的增加可以无限的逼近 IIR 滤波器。设计FSMN 的目的就是用 Feed forward neural network 去近似 RNN,对时间序列建模。RNN结构如下图:

2. 实现
2.1 网络结构
FSMN 的实现非常简单,就是在隐藏层之间插入 memory block,用于记录隐藏层节点的历史状态,如下图:

假设输入序列为\(X={x_1, x_2, …, x_T}\),其中\(x_i \in R^{D\times 1}\),第\(l\)个隐藏层的输出为\(H^l={h_1^l, h_2^l, …, h_T^l}\),其中\(h_i^l \in R^{D_l \times 1}\),论文中提出了两种形式的 FSMN:
- scalar FSMN(sFSMN):
其中\(a_i^l\)是标量。
- vector FSMN(vFSMN):
其中\(a_i^l\)是向量, \(\odot\)表示向量的点乘。
上述的定义中,可以称之为单向 FSMN,因为它只考虑了历史的序列信息,对于双向 FSMN,它的定义如下:
此时下一个隐藏层的输出为:
2.2 训练
以 N 阶 scalar FSMN 为例,memory block 会有 \(N+1\)个参数:\({a_0, a_1, a_2, …, a_N}\)。给定一个长度为\(T\)的序列输入\(X\)时,我们可以构造一个\(T \times T\)的参数矩阵\(M\):
对于双向的 FSMN 有:
因此,memory block 的计算可以表示为:
其中\(H\)表示隐层的序列输出,\(\tilde{H}\)表示 memory block 的序列输出。因此,对于一个 mini-batch \(L={X_1, X_2, …, X_K}\),memory block 的输出为:
因此,前向推导的时候,通过矩阵运算,很容易就可以使用 GPU 加速。在进行后向传播时,我们需要更新\(\bar{M}\)矩阵,假设关于\(\tilde{H}\)的误差为\(e_{\tilde{H}}\),那么有
关于\(\bar{H}\)的误差为
对于 vFSMN 的训练,可参考论文[2]。
3. 结构演化
3.1 FSMN
见上文。
3.2 cFSMN(compact-FSMN)
其结构如下图:
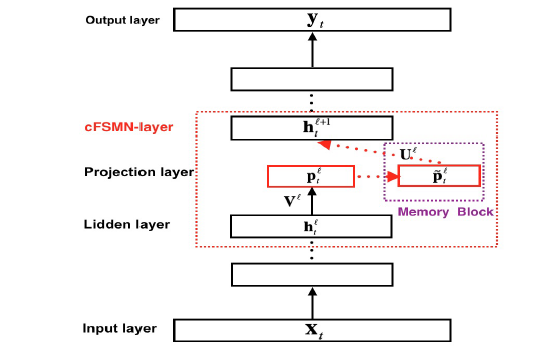 与 FSMN 相比,cFSMN可以看作在隐藏层后面又加了一个线性层,并且为线性层增加 memory block,并只将 memory block的输出作为下一层的输入,因此它的推导过程会有轻微的变化:
与 FSMN 相比,cFSMN可以看作在隐藏层后面又加了一个线性层,并且为线性层增加 memory block,并只将 memory block的输出作为下一层的输入,因此它的推导过程会有轻微的变化:
其中,\(p_t^l = V^l h^l_t + b^l\). 下一个隐藏层的输出为:
显然,当 FSMN 的线性变化层和 memory block 的权值矩阵相等时,FSMN 等价于cFSMN.
优点:
- 简化网络结构,减小参数空间大小
- 加速训练过程,性能基本保持不变
3.3 DFSMN(Deep-FSMN)
其结构如下图:
 借鉴了深度残差网络的思路,为了防止深度网络在训练过程中出现的梯度消失或弥散的现象,在 memory block 之间进行直接连接,因此网络的推导公式为:
借鉴了深度残差网络的思路,为了防止深度网络在训练过程中出现的梯度消失或弥散的现象,在 memory block 之间进行直接连接,因此网络的推导公式为:
其中,\(p_t^l = V^l h^l_t + b^l\). \(H(\cdot)\)表示 memory block 连接的变换,论文中使用了恒等变换,即
4. 总结
作者创造性的从滤波器理论中得到启发,用memory block 去逼近 RNN,在达到相似性能的同时,降低了网络的训练复杂度,在语音识别的任务上,取得了不错的性能。
Reference
[1] Zhang S, Jiang H, Wei S, et al. Feedforward sequential memory neural networks without recurrent feedback[J]. arXiv preprint arXiv:1510.02693, 2015.
[2] Zhang S, Liu C, Jiang H, et al. Feedforward sequential memory networks: A new structure to learn long-term dependency[J]. arXiv preprint arXiv:1512.08301, 2015.
[3] Zhang S, Jiang H, Xiong S, et al. Compact Feedforward Sequential Memory Networks for Large Vocabulary Continuous Speech Recognition[C]//INTERSPEECH. 2016: 3389-3393.
[4] Zhang S, Lei M, Yan Z, et al. Deep-FSMN for Large Vocabulary Continuous Speech Recognition[J]. arXiv preprint arXiv:1803.05030, 2018.