1 简介
通俗的讲,声纹识别就是辨别某一句话是不是由某一个人讲的。理论上,每个人声腔结构参数(尺寸等)都是不一样的,因此只要能提取到可以充分表达人与人之间声腔差异的特征,声音就可以像指纹一样,将不同的人有效区分。
声纹识别技术自上世纪40年代末开始,经历了一系列的技术演变逐步的走向成熟,并在这两年呈现了井喷式的发展。
1.1 声纹识别的分类
按照判别方式可分为:
- 说话人辨认(1:N,辨认未知说话人是已记录说话人中的哪一位)
- 说话人确认(1:1, 判断未知说话人是否为某个指定人)
按照音频内容可分为:
- 文本相关(未知说话人的说话内容固定不变)
- 文本无关(未知说话人的说话内容不确定)
按照测试人员集合可分为
- 开集(未知说话人不一定在已记录的说话人中)
- 闭集(未知说话人一定在已记录的说话人中)
1.2 评价指标
- 1:1
- False Rejection Rate
- False Acceptance Rate
- EER(Equal error rate, FAR==FRR)
- 1:N
1.3 技术演变
按照时间先后的发展,声纹识别技术演变可以大致分为:GMM-UBM -> GMM-SVM -> I-Vector PLDA -> DNN PLDA -> E2E(end to end)
2 GMM-UBM
高斯混合模型(GMM)是一系列的高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布。一个充分训练的GMM模型,可以比较好的表征说话人的空间。
在GMM-UBM方案的具体实现:
- Training
- 用大量不同说话人的数据EM算法训练UBM(Universal background model)模型(多个component的GMM模型)
- 针对每一个speaker,在UBM模型的基础上做MAP(Maximum a Posteriori Probability),得到每一个speaker的模型
- Estimation(Speaker verification)
- 对于某条utterance \(Y\), 定义:
- \(H_0\): \(Y\) 是Speaker \(S\) 说的
- \(H_1\): \(Y\) 不是Speaker \(S\) 说的
分别在speaker模型和UBM模型上计算似然度,按照如下准则进行判别
其中 \(\theta\) 为判别阈值。
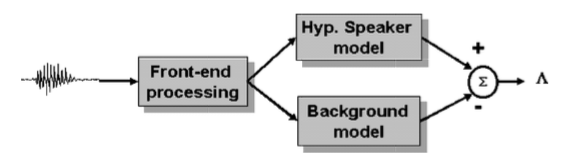
- 每个speaker的得分分布可能会不一致,因此对得分进行规整(Score Normalization),使得不同speaker服从一致的得分分布,可以进一步提升性能。
- 对于某条utterance \(Y\), 定义:
- Estimation(Speaker recognition) 与speaker verification类似,对score进行排序,得到nbest。
Reference
3 GMM-SVM
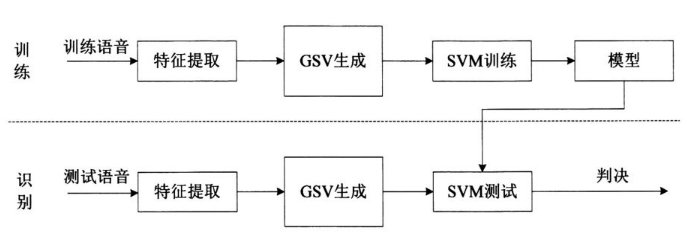
GMM-SVM(Support vector machine)的算法框图如下:
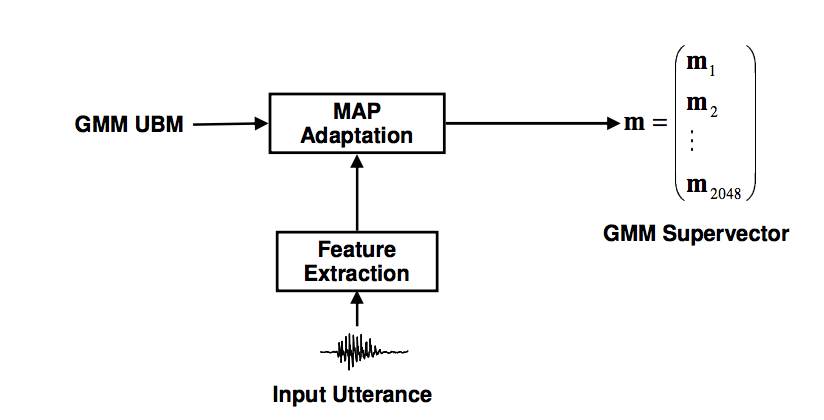
其中,GSV(GMM supervector)的生成就是将GMM中所有component的均值堆叠得到。
- Training
- EM训练得到UBM,然后对所有的speaker做MAP,得到每个speaker的GMM模型
- 提取每个speaker的supervector,训练SVM分类器
- Evaluation
- 针对utterance \(Y\),MAP计算得到它对应的supervector
- SVM分类器分类得到判决结果
GMM-SVM的提出,主要基于以下考虑:
- GMM是生成模型,SVM是判别模型,而说话人识别本质上是一个判别任务,相对来说SVM更加适合
- 每个GMM都可以用均值、协方差、权重三部分表示,用GMM对说话人建模,其均值矢量必然包含了大量的说话人和信道信息,SVM通过特征的非线性变换,可以更好的提取并区分说话人之间的差异信息。